

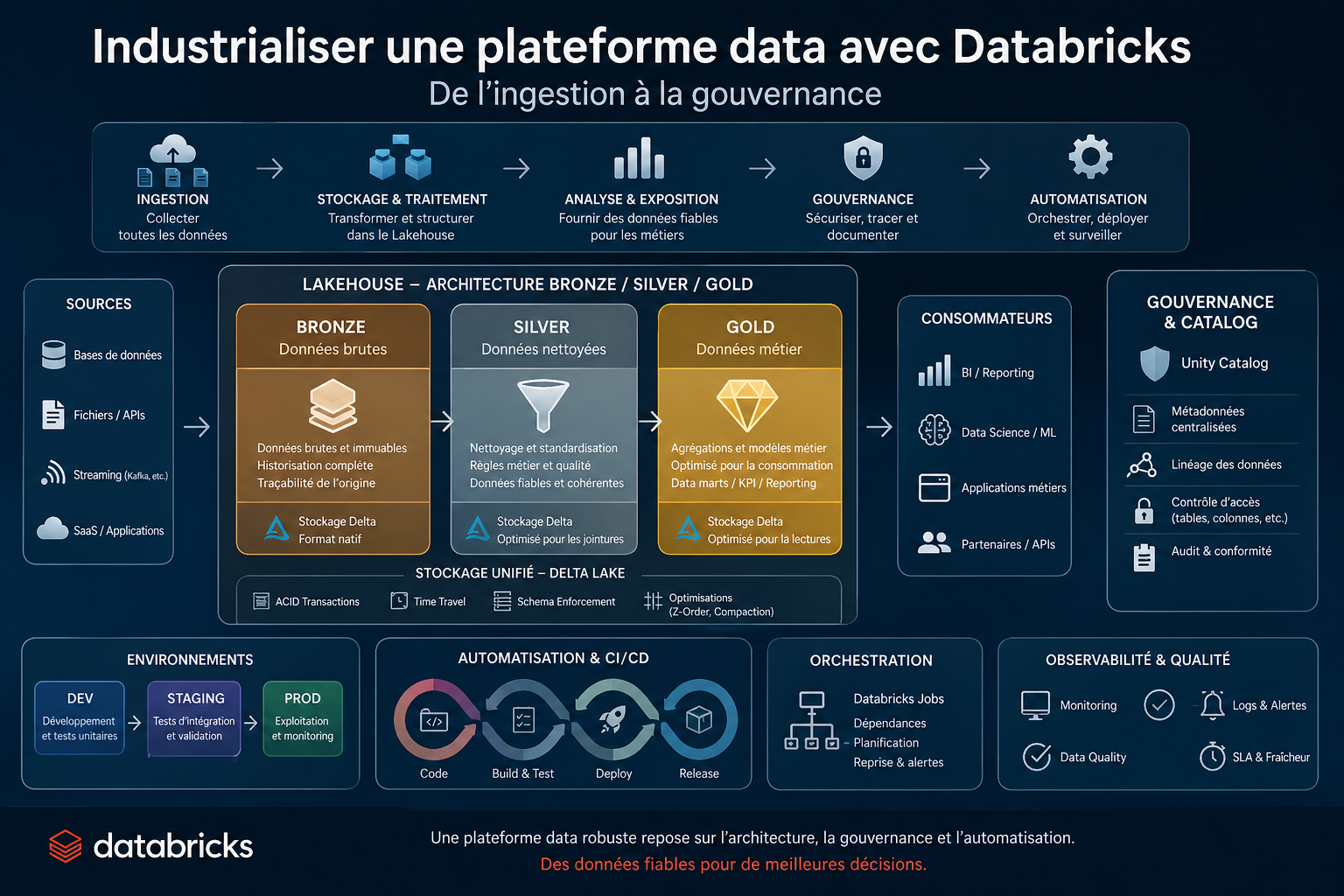
Industrialiser une plateforme data avec Databricks : une architecture pensée, pas empilée
Les plateformes data modernes échouent rarement à cause de la technologie. Elles échouent parce qu’elles sont conçues comme une juxtaposition de traitements, et non comme un système cohérent. Derrière l’apparente simplicité d’une plateforme comme Databricks se cache en réalité une exigence forte : penser la donnée comme un flux structuré, gouverné et évolutif.
Ce que l’on appelle aujourd’hui le Lakehouse n’est pas une simple convergence entre data lake et data warehouse. C’est une discipline d’ingénierie. Elle impose de distinguer ce qui relève du stockage et ce qui relève de l’usage, ce qui relève de la capture et ce qui relève de l’interprétation. Autrement dit : organiser le chaos initial des données en un système lisible, fiable et durable.
Pour y parvenir, il faut accepter une idée simple mais structurante : la donnée ne devient utile qu’à travers les transformations successives qu’on lui applique. C’est précisément ce que formalise le modèle Bronze / Silver / Gold.
De la donnée brute à la donnée métier : une progression nécessaire
Lorsqu’une donnée entre dans la plateforme, elle est, par nature, imparfaite. Incomplète, parfois incohérente, souvent dépendante de systèmes externes sur lesquels on n’a aucun contrôle. Vouloir la rendre immédiatement exploitable est une erreur classique. Cela revient à mélanger ingestion, nettoyage et logique métier dans un même mouvement — et donc à rendre le système fragile.
La couche Bronze existe précisément pour éviter cela. Elle n’a rien d’élégant, ni de “propre” au sens métier du terme. Elle est au contraire volontairement brute. On y conserve la donnée telle qu’elle arrive, enrichie uniquement d’informations techniques permettant de comprendre son origine et son moment d’ingestion. Ce choix, qui peut sembler coûteux ou redondant, est en réalité un investissement. Il garantit une propriété fondamentale : la rejouabilité.
Sans cette capacité à rejouer les traitements à partir d’une source fidèle, toute correction devient risquée, toute évolution devient incertaine. La Bronze n’est donc pas une simple zone de transit ; elle est la mémoire du système.
C’est dans la couche Silver que la donnée commence à devenir intelligible. Non pas encore utile au sens métier, mais au moins cohérente. On y corrige les anomalies, on y aligne les formats, on y applique des règles de validation. C’est un travail souvent sous-estimé, car il est peu visible. Pourtant, c’est ici que se construit la confiance dans la donnée. Une erreur introduite à ce niveau ne disparaît jamais vraiment ; elle se propage.
Enfin, la couche Gold marque un changement de nature. On ne travaille plus la donnée pour la rendre correcte, mais pour la rendre utile. Cela implique de faire des choix : quels indicateurs exposer, quelles agrégations privilégier, quelle granularité conserver. La donnée n’est plus seulement transformée, elle est interprétée. Et cette interprétation doit être explicite, documentée, assumée.
L’ingestion : un choix technique aux conséquences durables
On pourrait être tenté de considérer l’ingestion comme une simple étape d’entrée, presque mécanique. En réalité, elle conditionne tout le reste. Une ingestion mal pensée impose des contraintes permanentes aux couches aval.
Dans les architectures les plus simples, l’ingestion se fait par lots. Des fichiers arrivent, à intervalles réguliers, et sont traités en bloc. Cette approche a pour elle la robustesse et la lisibilité. Elle permet de comprendre facilement ce qui a été traité, quand, et comment relancer en cas d’échec. Mais elle introduit une latence structurelle : la donnée n’est jamais vraiment à jour, seulement “récemment mise à jour”.
À l’opposé, les architectures en streaming promettent une fraîcheur quasi immédiate. Les données sont intégrées au fil de l’eau, parfois événement par événement. Ce gain de réactivité a un coût : la complexité. Il faut gérer des flux continus, garantir que les traitements sont idempotents, comprendre des comportements parfois difficiles à reproduire. Le système devient plus sensible aux erreurs subtiles.
Entre ces deux approches, certaines solutions proposées par Databricks, comme Auto Loader, permettent de concilier simplicité et passage à l’échelle. En automatisant la détection des nouveaux fichiers et la gestion des incréments, elles retirent une part importante de la complexité opérationnelle. Mais là encore, l’outil ne remplace pas la réflexion : il faut toujours définir ce que signifie “ingérer correctement” une donnée.
Car au fond, l’ingestion n’est pas seulement un problème de transport. C’est un contrat implicite : à partir de quel moment considère-t-on qu’une donnée est entrée dans le système, et sous quelle forme elle pourra être rejouée, auditée, transformée.
Stocker n’est pas exposer : la séparation essentielle entre fichiers et tables
Une confusion fréquente dans les projets Databricks consiste à assimiler les données aux fichiers qui les contiennent. Or, cette vision est trompeuse. Les fichiers — généralement stockés dans un data lake sous forme de tables Delta — ne sont qu’une implémentation physique. Ils répondent à des contraintes de performance, de distribution et de stockage. Mais ils ne doivent jamais devenir l’interface d’accès à la donnée.
C’est précisément pour éviter cette dérive que des couches comme Unity Catalog existent. Elles introduisent une abstraction : au lieu de manipuler des chemins de fichiers, on manipule des tables organisées en catalogues et schémas. Cette abstraction n’est pas un luxe ; elle est une condition de gouvernance.
Sans elle, il devient impossible de contrôler finement les accès, de tracer l’utilisation des données, ou même de faire évoluer l’organisation physique sans impacter les usages. Avec elle, on peut déplacer une table, changer son mode de stockage, optimiser ses performances, sans que les utilisateurs n’aient à modifier leurs requêtes.
Cela suppose toutefois une discipline stricte : ne jamais contourner le catalogue pour accéder directement aux fichiers. Le stockage doit rester invisible pour les consommateurs de données. Il est une fondation, pas une interface.
Structurer un projet : écrire moins, organiser mieux
Un projet Databricks mal structuré ne devient pas immédiatement inutilisable. Il se dégrade progressivement. Les notebooks s’allongent, les dépendances implicites se multiplient, les comportements deviennent difficiles à anticiper. Et un jour, toute modification devient risquée.
Éviter cette dérive demande une organisation claire dès le départ. Non pas une organisation rigide, mais une séparation explicite des responsabilités. L’ingestion, la transformation et l’exposition doivent être pensées comme des étapes distinctes, même si elles partagent des briques techniques.
Cette séparation permet une autre propriété essentielle : la testabilité. On ne teste pas un pipeline monolithique, on teste des étapes. On ne corrige pas un système entier, on corrige un maillon.
Le versioning joue ici un rôle déterminant. Intégrer Databricks à un système de gestion de code comme Git n’est pas une option de confort, mais une nécessité. Il ne s’agit pas seulement de conserver un historique, mais de rendre les changements visibles, discutables, réversibles. Une plateforme data est un logiciel ; elle doit être traitée comme tel.
Suivre et comprendre : rendre les pipelines observables
Une plateforme data qui fonctionne sans être observée est une illusion. Elle semble stable jusqu’au moment où un problème apparaît — et où il devient difficile de comprendre ce qui s’est réellement passé.
Le suivi des pipelines ne doit donc pas se limiter à vérifier qu’un job s’est exécuté. Il doit permettre de répondre à des questions précises : quelles données ont été traitées ? lesquelles ont échoué ? à quel moment une anomalie est-elle apparue ?
Cette exigence conduit naturellement à intégrer des mécanismes de contrôle de qualité des données. Non pas comme une étape finale, mais comme une composante continue du pipeline. Tester qu’une colonne ne contient pas de valeurs nulles, qu’un identifiant est unique, qu’un volume de données reste cohérent dans le temps — ces vérifications simples constituent une première ligne de défense contre les dérives.
À cela s’ajoute la notion de fraîcheur : une donnée correcte mais obsolète est souvent aussi problématique qu’une donnée erronée. Suivre les délais de traitement devient alors aussi important que suivre leur succès.
Documenter : transformer un système technique en produit exploitable
Une plateforme non documentée fonctionne uniquement pour ceux qui l’ont construite. Dès qu’elle doit être partagée, elle devient opaque.
La documentation ne doit pas être perçue comme une contrainte externe, mais comme une extension naturelle du système. Décrire un pipeline, expliciter une règle métier, documenter une table — ce sont autant de façons de rendre la plateforme intelligible.
Les outils comme Unity Catalog facilitent cette démarche en centralisant les métadonnées et en permettant de tracer les dépendances entre les jeux de données. Mais là encore, l’outil ne fait pas tout. Une documentation utile est une documentation qui répond à des questions concrètes : d’où vient cette donnée ? que signifie-t-elle ? peut-on lui faire confiance ?
Environnements : la condition silencieuse de l’industrialisation
Jusqu’ici, la plateforme a été décrite comme un système logique : des données qui circulent, se transforment, se structurent. Mais cette vision reste incomplète tant qu’on ne s’intéresse pas à une autre dimension, plus discrète mais tout aussi déterminante : celle des environnements.
Car une plateforme data n’est pas figée. Elle évolue en permanence. Des règles métier changent, des sources apparaissent, des corrections sont nécessaires. Et chaque modification pose une question simple, mais critique : comment la tester sans risquer de compromettre ce qui fonctionne déjà ?
C’est précisément le rôle de la séparation entre développement, staging et production.
L’environnement de développement est celui de l’exploration et de la construction. On y teste des hypothèses, on y manipule des volumes réduits, on y accepte une certaine instabilité. C’est un espace de liberté, mais aussi un espace dangereux si ses artefacts sont confondus avec ceux de production. Une table mal nommée, un chemin mal paramétré, et c’est toute la chaîne qui peut être impactée.
L’environnement de staging introduit une rupture essentielle. Il ne s’agit plus d’expérimenter, mais de valider. Les pipelines y sont exécutés dans des conditions proches de la production : mêmes volumes, mêmes dépendances, mêmes contraintes. C’est ici que l’on vérifie non seulement que le code fonctionne, mais qu’il se comporte correctement dans un système réel. Trop souvent négligé, cet environnement est pourtant celui qui permet d’éviter les erreurs les plus coûteuses.
Enfin, la production n’est pas un terrain de test. C’est un espace de confiance. Les données qui y sont exposées sont consommées par des utilisateurs, intégrées dans des décisions, parfois critiques. Toute modification doit y être maîtrisée, traçable, réversible. Cela implique une discipline forte : aucun déploiement manuel, aucune modification directe, aucun contournement des processus établis.
Cette séparation n’est pas seulement logique, elle est aussi technique. Elle se matérialise par :
- des catalogues distincts (par exemple
dev,staging,prod) - des chemins de stockage isolés
- des configurations propres à chaque environnement
- des droits d’accès différenciés
Mais au-delà de ces mécanismes, c’est une philosophie qui s’impose. Une plateforme data mature est une plateforme où l’on ne “corrige” pas en production. On corrige en développement, on valide en staging, puis on déploie.
Cette approche transforme profondément la manière de travailler. Elle introduit de la rigueur, parfois perçue comme une contrainte. Mais elle permet surtout de rendre les évolutions prévisibles. Et dans un système où la donnée est au cœur des décisions, la prévisibilité est une qualité rare — et précieuse.
Il devient alors évident que les environnements ne sont pas un détail d’implémentation. Ils sont la condition même du passage d’un projet artisanal à une plateforme industrielle.
Automatiser : passer d’un projet à une plateforme
Il existe une différence fondamentale entre un projet data et une plateforme data : la reproductibilité. Un projet peut fonctionner de manière artisanale ; une plateforme ne le peut pas.
L’automatisation est ce qui permet de franchir ce cap. Automatiser les déploiements, les tests, l’exécution des pipelines, la gestion des ressources — tout cela contribue à réduire la dépendance aux interventions humaines. Non pas pour les éliminer, mais pour les rendre plus fiables.
Les mécanismes de CI/CD, souvent associés au développement logiciel, trouvent ici une application directe. Chaque modification doit pouvoir être testée, validée et déployée de manière contrôlée. De même, l’infrastructure elle-même doit être décrite comme du code, afin de garantir qu’elle peut être recréée à l’identique.
Sans cette discipline, la plateforme reste fragile. Avec elle, elle devient un système industriel.
Conclusion
Concevoir une plateforme data avec Databricks ne consiste pas à empiler des technologies, mais à organiser des principes. Le modèle Bronze / Silver / Gold structure la transformation des données. La séparation entre stockage physique et organisation logique garantit la gouvernance. L’ingestion, la structuration, le suivi, la documentation et l’automatisation assurent la robustesse de l’ensemble.
Ce qui distingue une plateforme qui fonctionne d’une plateforme qui dure, ce n’est pas la sophistication de ses outils, mais la cohérence de ses choix. Une architecture bien pensée n’est pas seulement efficace aujourd’hui ; elle reste compréhensible demain.
Pour aller plus loin : prolongements naturels
Une fois ces fondations en place, plusieurs approfondissements s’imposent naturellement :
- comment formaliser une véritable stratégie de qualité des données
- comment optimiser les performances des tables Delta à grande échelle
- comment mettre en place un CI/CD complet adapté aux pipelines data
- comment exploiter pleinement Unity Catalog pour la gouvernance
- comment concevoir des modèles analytiques adaptés aux usages métier
- comment rendre les pipelines réellement observables
- comment maîtriser les coûts d’infrastructure
- comment intégrer des cas d’usage de machine learning
- comment sécuriser finement les accès aux données
- comment gérer l’évolution des schémas dans le temps
Chacun de ces sujets prolonge le même objectif : faire passer la plateforme d’un outil technique à un véritable actif stratégique.